

La traducción automática (TA) es una herramienta esencial para mejorar la comunicación entre lenguas, especialmente para aquellas con menor presencia digital, como el gallego. En imaxin, con más de 25 años de experiencia en el desarrollo de soluciones lingüísticas, mantenemos un compromiso constante con la innovación en traducción automática. La rápida evolución de la inteligencia artificial hace imprescindible conocer y evaluar los recursos más avanzados disponibles, tanto para la traducción automática como para otras áreas del procesamiento del lenguaje natural (PLN).
Recientemente, en colaboración con la Universidad del País Vasco (EHU), nuestra compañera Sofía García realizó una investigación dentro de su tesis industrial, centrada en identificar los sistemas de traducción automática más efectivos para el gallego. Este estudio, adaptado a las necesidades de una pequeña y mediana empresa (pyme), representa la evaluación más exhaustiva realizada hasta el momento en la traducción automática para el gallego, además del primer estudio en TA que incluye el portugués-gallego dentro de una evaluación genérica. Los resultados de este análisis fueron presentados el pasado 25 de septiembre en el congreso anual de la Sociedad Española del Procesamiento del Lenguaje Natural (SEPLN) 2025, celebrado en Zaragoza.
En este congreso, reconocido como un evento de referencia en tecnologías del lenguaje en el ámbito hispano, tuvimos la oportunidad de conectar con empresas e instituciones del PLN tanto a nivel estatal como internacional. Este encuentro facilitó el intercambio de conocimientos y la creación de lazos tanto académicos como empresariales. Además, escuchamos intervenciones de figuras destacadas en el sector, como Marta R. Costa-jussà, investigadora científica en META, así como de otros expertos de diversas disciplinas, lo que nos permitió ampliar nuestra perspectiva e identificar nuevas oportunidades para innovar dentro de nuestra empresa.
Objetivo del estudio
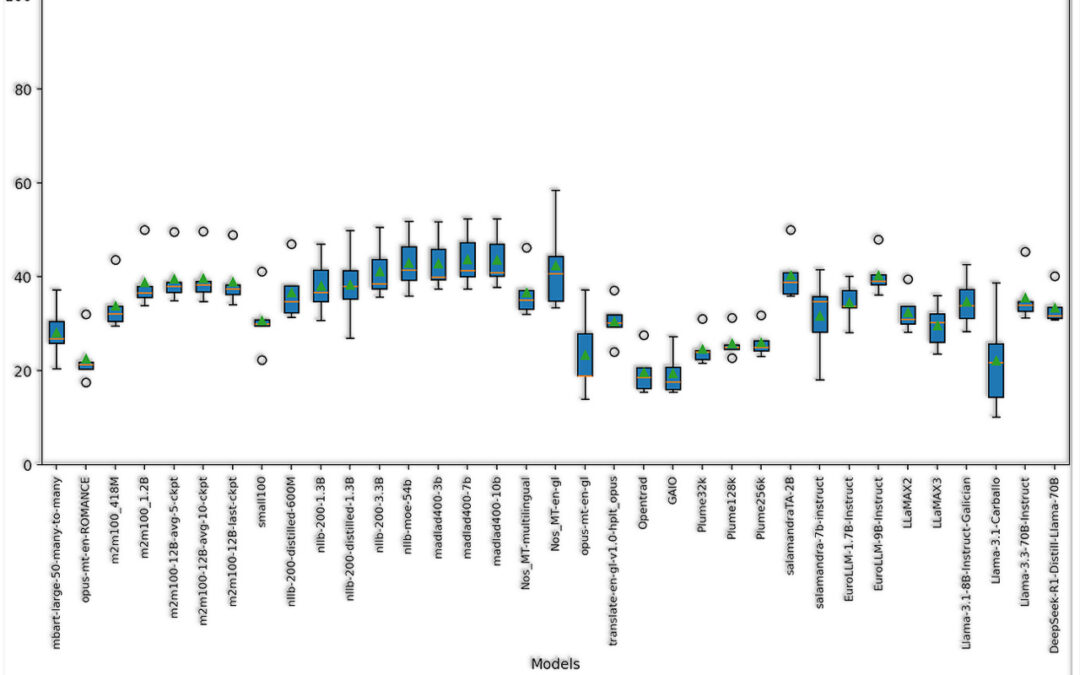
El estudio tenía como objetivo identificar los modelos de traducción automática de licencia libre más efectivos para los pares de lenguas inglés‑gallego, español‑gallego y portugués‑gallego en el dominio general. Entre los tres pares, se evaluaron un total de 45 sistemas en 23 tests de evaluación teniendo en cuenta tres factores principales:
-
- Calidad del modelo: precisión de las traducciones producidas
- Varianza en el rendimiento: consistencia de los modelos en distintos datasets de evaluación
- Tamaño del modelo: eficiencia computacional en el contexto de una pyme
Metodología
La investigación evaluó cuatro tipos principales de sistemas de traducción automática:
-
- Sistemas basados en reglas: Apertium. Para esta evaluación no se utilizó la versión liberada, sino el sistema de pago de nuestra plataforma Opentrad, también implantado en Gaio, el sistema de traducción automática oficial de la Xunta de Galicia.
- Modelos neuronales bilingües: sistemas sequence-to-sequence especializados en un par de lenguas.
- Modelos neuronales multilingües: sistemas sequence-to-sequence que incluyen múltiples lenguas simultáneamente.
- Grandes modelos de lenguaje (LLM): tanto no instruidos, como Llama-3.1.-Carballo; instruidos, como los modelos de EuroLLM; o ajustados para traducción automática, como los modelos de LlaMAX.
Principales resultados
-
- Español-gallego: donde los más pequeños aún compiten
Para el par español-gallego, el sistema Opentrad y el modelo neuronal bilingüe del Proxecto Nós siguen siendo competitivos con los modelos multilingües y los LLM. Esto demuestra que entre lenguas próximas y de pocos recursos, los sistemas más pequeños aún pueden funcionar. De manera que, además de dar buenos resultados, ahorran costes económicos y computacionales y son una alternativa menos contaminante que modelos más grandes. - Inglés-gallego: la fuerza de los modelos multilingües
Para el par inglés-gallego, los modelos multilingües como madlad demostraron una calidad superior, aprovechando el conocimiento que tienen de distintas lenguas de muchos recursos (high resource languages, HRL) para hacer transferencia de conocimientos a las lenguas con menos recursos (low resource languages, LRL). - Portugués-gallego: un campo por explorar
El par portugués-gallego dio unos resultados sorprendentemente bajos en cuanto a métricas. A pesar de ser dos lenguas muy próximas, los resultados cayeron por debajo del inglés-gallego de media. Esto llama la atención, ya que normalmente los pares de lenguas próximas obtienen mejores resultados que los pares de lenguas más distantes.
Uno de los posibles motivos fue la escasez de tests de evaluación. Para portugués-gallego solo existen tests de referencia multilingües y de dominio genérico, conocidos como benchmarks, la mayoría con las variantes europea y brasileña mezcladas. Por esta razón, consideramos los resultados inconclusos. Urge la creación de buenos tests de evaluación en este par de lenguas, tanto de dominio genérico como específico y que permitan evaluar propiamente la variante europea del portugués, por ser esta de gran interés dada la cercanía lingüística y geográfica entre el gallego y el portugués europeo.
Ciñéndonos propiamente a la evaluación hecha en el artículo, el modelo nllb-muele-54b, uno de los modelos multilingües más pesados, fue el que obtuvo mejores resultados en cuanto a las métricas de evaluación de la calidad. Aun así, reiteramos la necesidad de investigar este par con más profundidad para conseguir modelos más excelentes, tanto a nivel de calidad como de coste computacional.
- Español-gallego: donde los más pequeños aún compiten
Contribuciones y futuro
Los hallazgos de este estudio ofrecen orientaciones prácticas para los tres pares de lenguas y pretenden ser una guía tanto para el ámbito de la investigación como para el empresarial. Para ver los modelos evaluados, los mejor valorados o consultar más información sobre los otros factores de evaluación, descargue la guía cubriendo el formulario que encontrará al final de la página.
Compromiso con las lenguas minorizadas
En imaxin buscamos dar siempre la mejor calidad a nuestros clientes y, hoy en día, en el ámbito de la inteligencia artificial, esto no sería posible si no fuésemos de la mano de la investigación. Este último trabajo se une a otros focalizados en el gallego y en otras lenguas minorizadas como:
-
- BLARK, herramienta para evaluar el estado de las lenguas minorizadas en la inteligencia artificial en cuanto a sus recursos. Esta herramienta se desarrolló junto al Proxecto Nós en el European Language Equality del 2023.
- Primer modelo neuronal gallego-portugués: modelo desarrollado para el PROPOR 2024, congreso del que fuimos patrocinadores.
- Sistema español-asturiano presentado en la Shared Task del WMT24: Translation into Low-Resource Languages of Spain (Traducción a las lenguas de pocos recursos de España).
Esta investigación destaca la importancia de desarrollar soluciones específicas para lenguas como el gallego, sin depender exclusivamente de plataformas generales. Además, refuerza el papel de la colaboración entre empresa y universidad para abordar retos tecnológicos complejos. Gracias a estos resultados, tenemos un conocimiento más profundo de los recursos disponibles y del camino a seguir para mejorar los sistemas de traducción automática que tenemos implantados.
Formulario de descarga
Aviso legal
RESPONSABLE: FACTORÍA DE SOFTWARE E MULTIMEDIA, S.L.
FINALIDAD DEL TRATAMIENTO Y LEGITIMACIÓN: Responder a la solicitud o consulta de la persoa interesada e en su caso, enviarle información relacionada sobre los servicios de imaxin|software, contando con su consentimiento.
DESTINATARIOS: No se cederán datos a terceros.
EJERCICIO DE DERECHOS: Se permite el ejercicio de los derechos de acceso, rectificación o supresión, la limitación del tratamiento, oposición y el derecho a la portabilidad de sus datos. Tambien podrá revocar su consentimiento en cualquier momento en Salgueiriños de abaixo 11 Local 6 15703, Santiago de Compostela (A Coruña) o enviando un correo electrónico a lopd@imaxin.com
INFORMACIÓN ADICIONAL: Podrá obtener toda la información detallada de nuestra Política de Privacidade