
What is the BLARK?
In 2023 we were selected, along with 8 other projects, to participate in the SRIA Contribution Projects. Our work consisted of creating a BLARK (Basic Language Resource Kit) for minority languages in the deep learning era, using Galician as an example.
The BLARK is a tool that allows measuring the minimum requirements that any minority language must meet to be competitive in Language Technologies (LT) and assessing the status of each language with respect to those requirements. This is why this tool would not make sense for languages such as English, or slightly smaller ones such as Spanish, German or Portuguese, as they would perfectly cover these minimum requirements.
The first BLARKs emerged in the late 1990s and early 2000s for languages such as Dutch or Arabic. But two decades later, LT underwent a paradigm shift with the advent of neural networks, making it necessary to update this tool.
Development process
To carry out this work, an analysis was first conducted of existing resources in various minority languages such as Catalan, Galician or Basque, as well as other large languages that have not yet reached the LT development levels of languages such as English or Chinese, for example Spanish or German. An analysis was also made of the current state of LT in the deep learning era.
In this way, the new BLARK was divided into Transversal Resources, that is, all those tools and resources that can be used for any LT task; and Specific Tasks, such as machine translation, text correction, speech processing and synthesis, etc. This allows the resources of each language to be assessed, both at a generic level and at the specific level of each task (models and data). It is important to note that, especially in the case of specific tasks, since this is a BLARK for the deep learning era, only neural models are considered for performing those tasks. Previous systems, such as rule-based ones, are not considered for this BLARK, as the aim is to know the level of development in deep learning.
Evaluation system
Before detailing the table of our BLARK, we will briefly explain how the evaluation system works. As already explained above, the BLARK is a tool for assessing the status of minority languages in LT and the resources they have available. In this case, and unlike previous BLARKs, a quantitative evaluation system was implemented. Below is an example of the generic BLARK table.
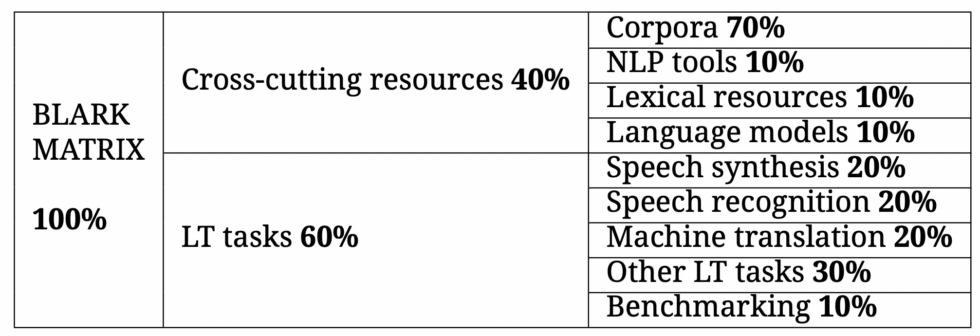
As can be observed, each section has a value (transversal resources): 40%; LT tasks: 60%). In this case, greater weight was given to specific tasks, as deep learning requires trained models to carry out each task and corpora with specific characteristics to train or improve such models. Although transversal resources may be useful, each task requires specific models and corpora.
Furthermore, each section is divided into a series of subsections that also have their own weight within the corresponding section. And each subsection will consist of a series of resources that will also have their own value, as will be seen in subsequent posts.
Finally, to evaluate each resource, it was decided to take into account its size (small, medium or large), its quality (low, medium or high) and its licence (closed, open only for research or completely open). Evaluating by licence is important, as many resources cannot be used for certain purposes, especially commercial ones. This means that, even if resources exist, they may not be truly usable.
To better visualise how the BLARK works and what results it can provide, subsequent posts will show the results for Galician in this BLARK, detailing the table by subsections.
Transversal resources — corpora

Corpora is the first subsection of transversal resources. In general, a corpus is a set of texts that may be annotated (corpora containing morphological, syntactic, semantic information, etc., such as the Corpus Técnico do Galego, CTG); they may be reference corpora (corpora that collect the different varieties of a language, such as temporal, geographical, social ones… such as the CORGA in Galician), or they may be macro corpora (very large corpora usually extracted from various Internet sources). In Galician, the SLIGalWeb stands out. As can be seen in the table, there is currently a large amount of annotated and freely available corpora for Galician, but of low quality. In addition, the CORGA is not freely available, and the SLIGalWeb, despite being a large corpus, is of medium size for what a macro corpus should be. There is still work to be done in the development of corpora for the Galician language, especially for training neural models.
Transversal resources — NLP tools

Other fundamental transversal resources are Natural Language Processing (NLP) tools, which are used to process text before training so that it can be interpreted by the model. These tools are usually not found separately, but are included in libraries such as Linguakit or Freeling, which include the Galician language. And, nowadays, they are already incorporated into the various existing models for task development.
Some of the most notable tools are: tokenisers (which divide texts into fragments (tokens)), POS-taggers (which perform a morphological analysis of text), language recognisers, and named entity recognisers and classifiers (NERC). As these tools were already widely used in the pre-deep learning era, Galician is very well developed in this subsection.
Transversal resources — lexical resources
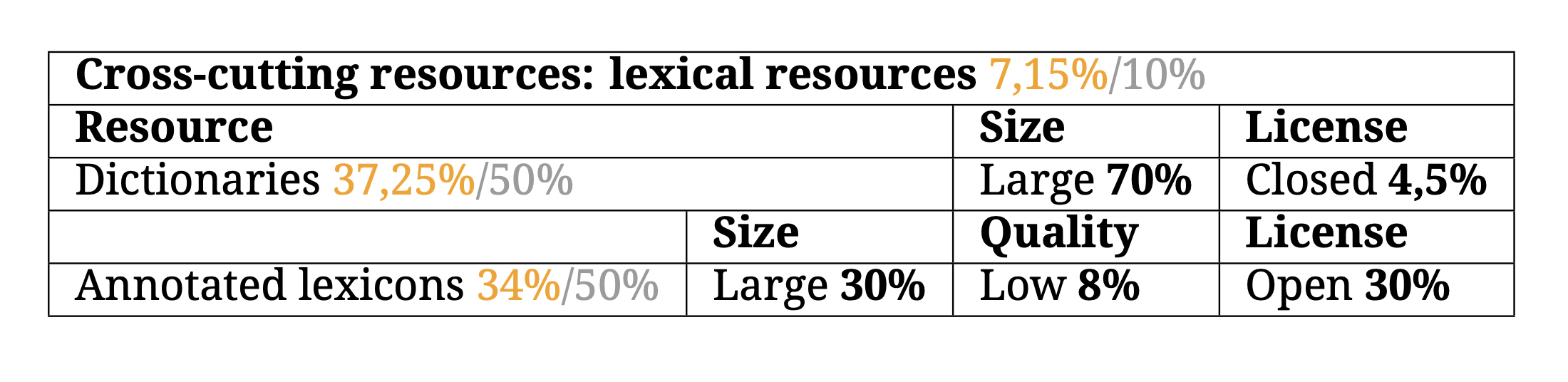
Unlike corpora, which are sets of texts, lexical resources are understood to be all those documents that collect lists of words. The most basic and indispensable lexical resources today are dictionaries (such as the dictionary of the Real Academia Galega, RAG) or annotated lexicons (such as GalNet). Although the RAG dictionary is a large resource, it is closed for use and the annotated lexicons available for Galician are of low quality. Again, there is also work to be done in the development of lexical resources.
Transversal resources — language models
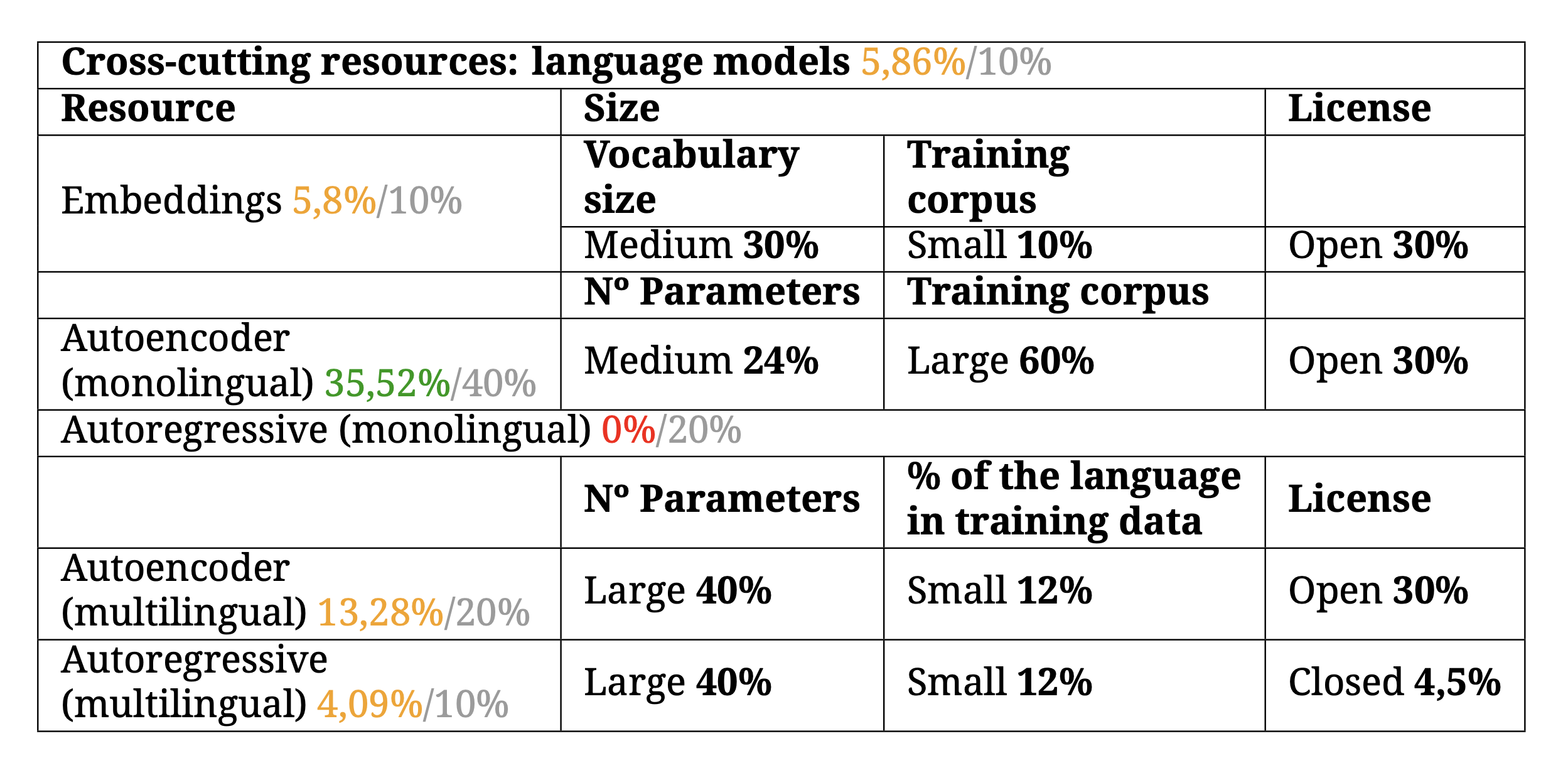
Language models, such as the well-known GPT, are models that “learn” a language from training on vast amounts of raw text from a specific language in the case of monolingual models and from several languages in the case of multilingual ones. Once these models learn the language, they can be fine-tuned to carry out various tasks very effectively, such as morphological tagging, entity recognition, automatic summarisation, sentiment analysis, etc.
As shown in the table, language models can be divided into embeddings (vector representations of words or phrases), autoencoders (such as BERT models, which learn to predict the next word by taking into account the context around the word) and autoregressive models (such as GPT models, which can predict the next word by taking into account only the context preceding that word). Currently, Galician has its own embeddings and autoencoder models, both monolingual (Bertinho, BERT-small, BERT-base and BERT-large) and multilingual, such as mBERT.
Regarding autoregressive models, Galician is present in the multilingual GPT model but, for now, does not have its own language model. Galician is moderately developed in this area, especially due to the development of monolingual BERT models, but its presence in multilingual models, both in mBERT and in mGPT, is limited.
LT tasks — speech synthesis
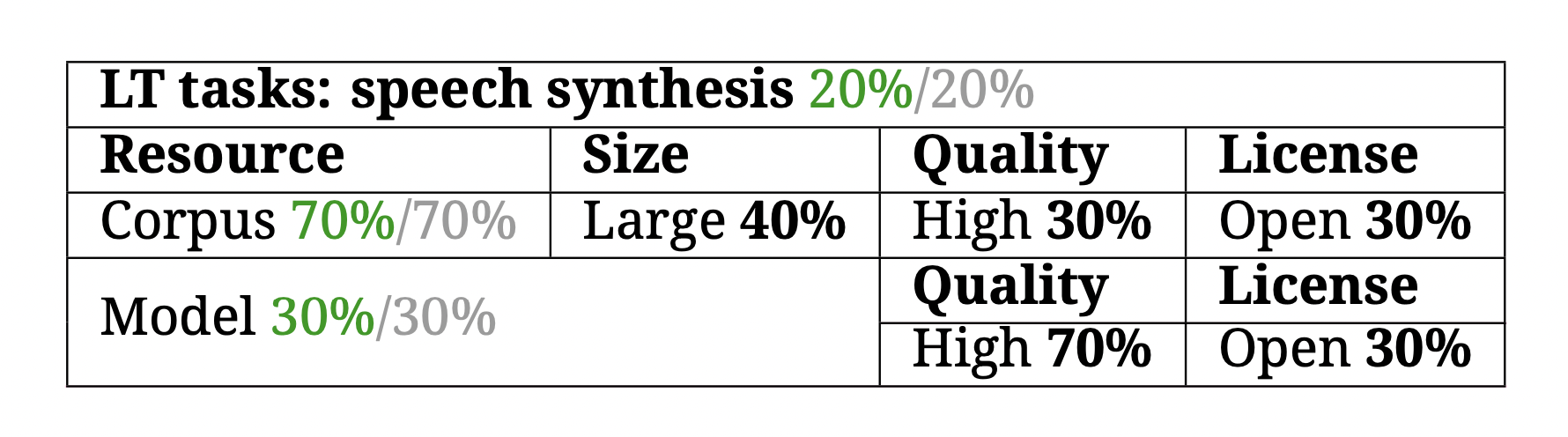
Speech synthesis or Text-to-Speech (TTS) is the task of synthesising a text and converting it into audio. Thanks to the work carried out by the Proxecto Nós in the past year, Galician currently has a high-quality and fully open corpus and model for carrying out this task. Although there is still research to be done, Galician would achieve the maximum score in this BLARK task.
LT tasks — speech recognition
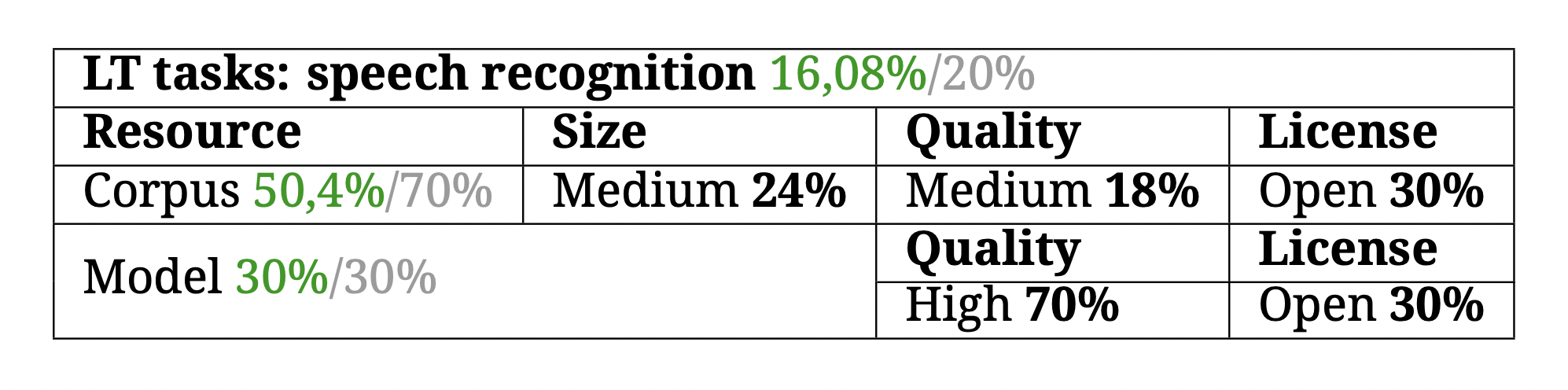
Speech recognition or Automatic Speech Recognition (ASR) is the task of recognising and transforming audio into text. As mentioned in the previous post, the Proxecto Nós has created a series of high-quality corpora and a model that allows Galician to achieve a high score in this task. Nevertheless, as also previously mentioned, there is still a great deal of research to be done in this area.
LT tasks — machine translation
Machine translation is the task of translating a text from a source language to a target language by means of computational systems. In deep learning there are bilingual models, which are capable of translating between a pair of languages, or multilingual models, which can translate between many different languages with a single model. To assess the state of a language in machine translation, up to a maximum of four translation pairs are evaluated (since a larger number of translation pairs would not be characteristic of a minority language, but rather of a highly developed one). In the case of multilingual models, this BLARK only considers those that have been fine-tuned for the specific language. This is why, in the case of Galician, only the Spanish-Galician and English- Galician pairs were considered, despite Galician being present in different multilingual models such as M2M or NLLB.
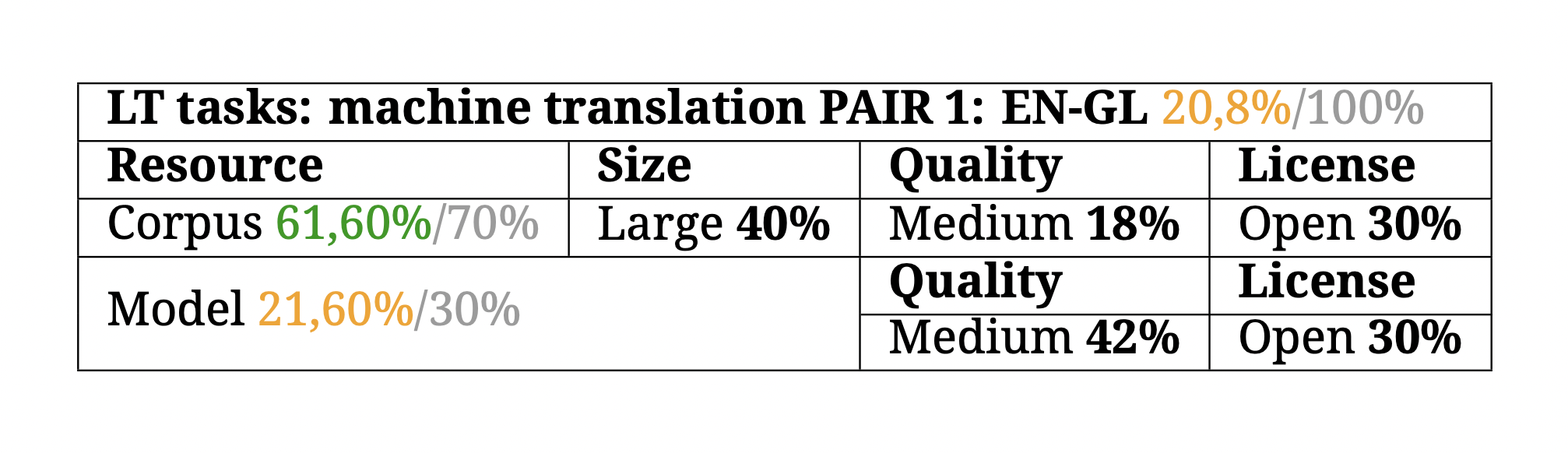
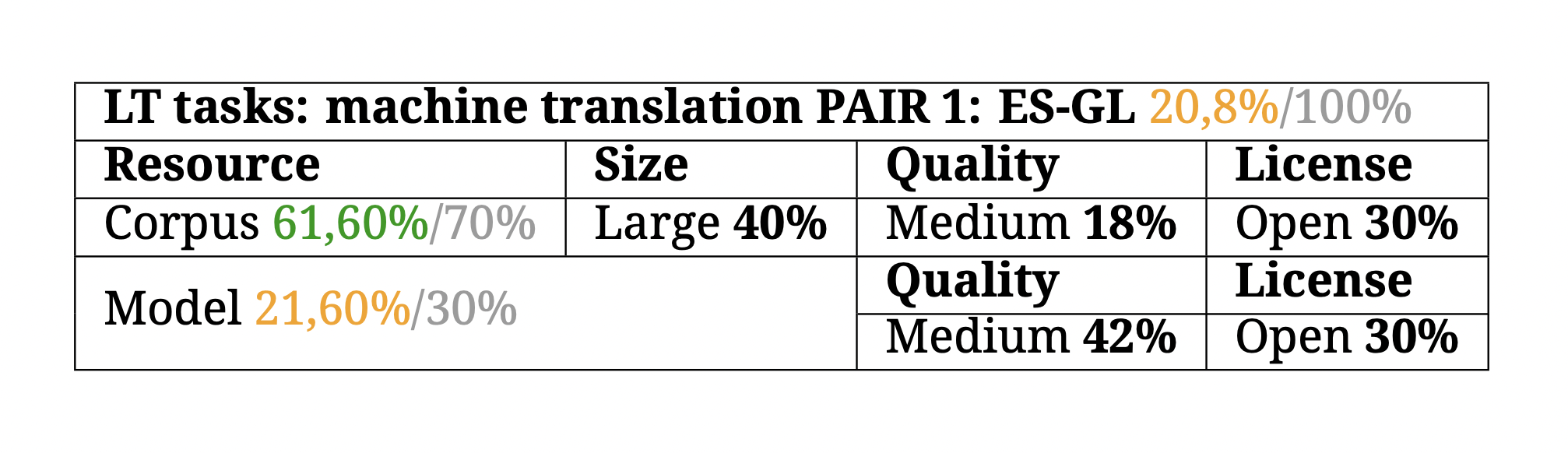
Again, the Proxecto Nós created parallel corpora and translation models for the Spanish-Galician and English-Galician pairs. Furthermore, a Spanish-Galician translation model already existed, created by PlanTL.
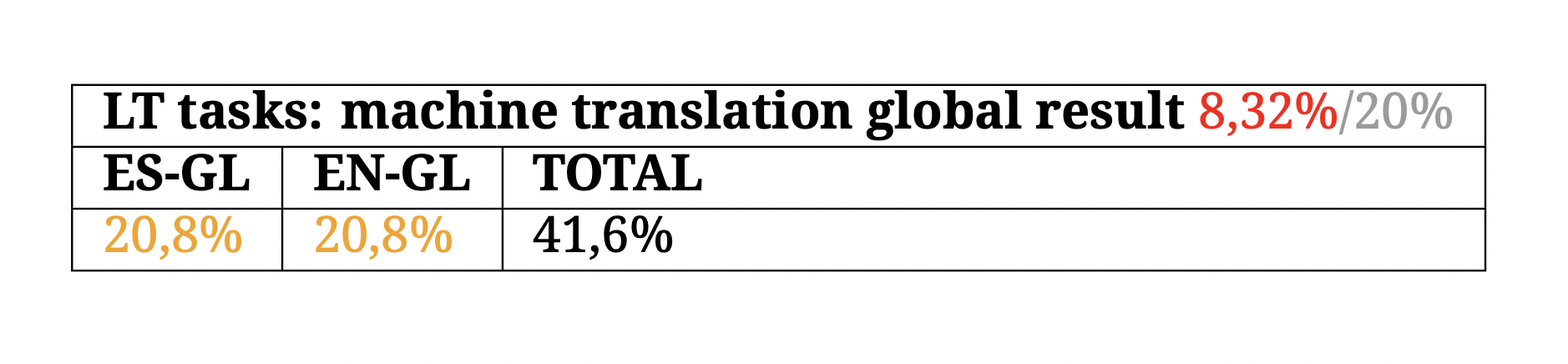
And finally, regarding corpora, there are multiple multilingual corpora that include Galician but usually of poor quality. This is why the overall machine translation score for Galician in the BLARK is low. There are only neural models for translating between two translation pairs, and at corpus level, although these are large, the quality is generally medium-low.
LT tasks — other tasks
Both speech synthesis and recognition and machine translation are basic LT tasks that all languages should have covered as a minimum in deep learning. However, there are a number of tasks that, while important, are barely covered even in developed languages such as Spanish or Portuguese, and are only well developed in English.
This is why all these tasks have been included in the BLARK but in their own category (Other LT Tasks). These are as follows:
- Grammatical Error Correction (GEC). This task consists of automatically detecting errors in a text, whether orthographic, grammatical, semantic or stylistic, and correcting them.
- Automatic Summarisation. This task consists of converting an original text into a more compact one that does not lose the main information of the original.
- Sentiment Analysis. This task consists of determining the polarity of a text by classifying it as positive, negative or neutral. It is commonly used, for example, to find out the opinions of different consumers about various products.
- Fact Verification. This task consists of determining whether the statement made in a given text is true or false. It is commonly used for fraud detection.
- Dialogue Systems. These integrate a variety of subtasks and resources that enable human-machine interaction, such as mobile assistants, chatbots, smart speakers, etc.
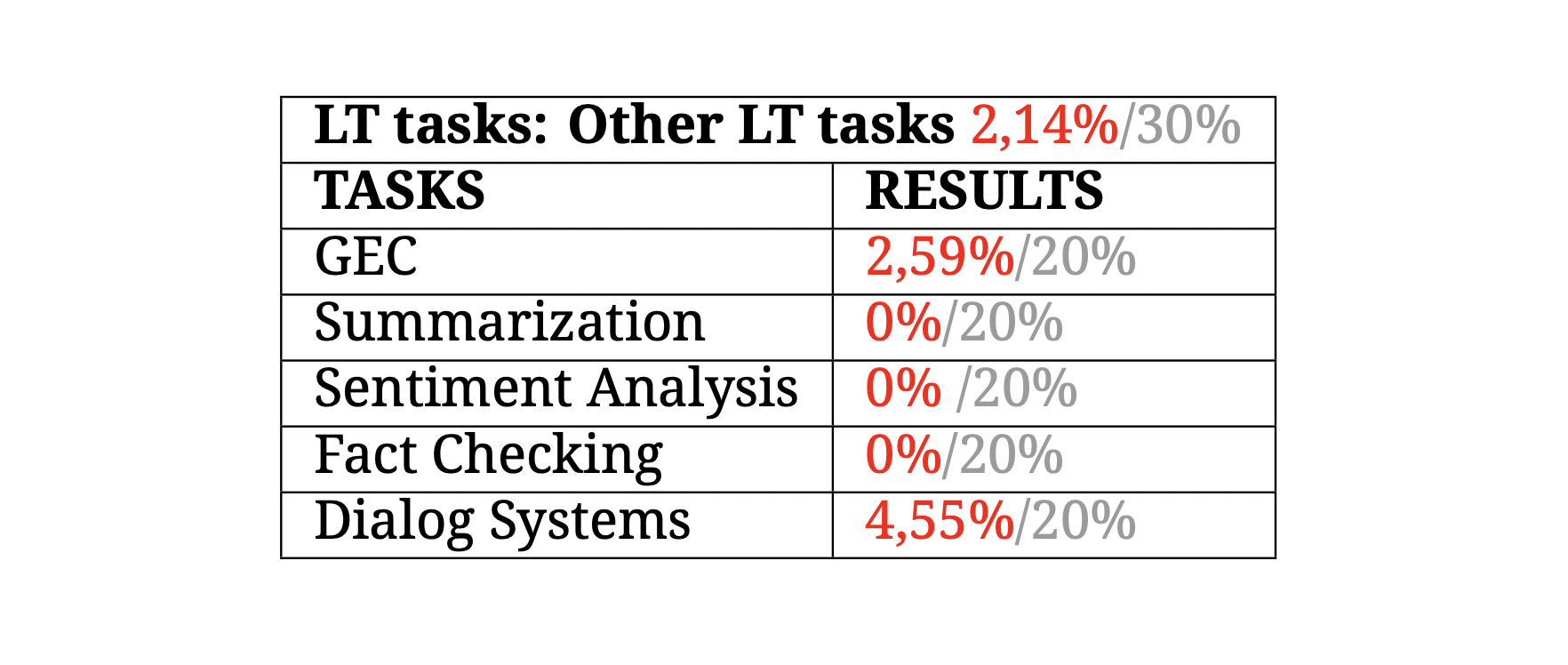
As can be seen in the table, these tasks in Galician are practically non-existent. In the grammatical error correction task there are some small, low-quality corpora, and in dialogue systems there are some systems developed for public administration, but there is no trained model for any of the other tasks nor sufficient corpora to train new models. As already mentioned, these are not basic tasks, but it would be necessary to develop them in the future to guarantee Galician speakers these tools in their language.
LT tasks — evaluation systems
In this last subcategory, the existence of various resources for evaluating the models of the specific tasks mentioned above was analysed in a very general way. These systems can be both datasets (corpora reviewed by linguists to provide a benchmark for what the model does) or language-dependent automatic evaluation methods, such as COMET for machine translation.

In general, Galician does not have evaluation methods that would allow the assessment of models or comparative analyses with other languages across the different tasks. This is why the score in this subsection is very low. Having evaluation systems is fundamental, as it makes it possible to know how well a model works and to compare it with the state of the art.
GL-BLARK
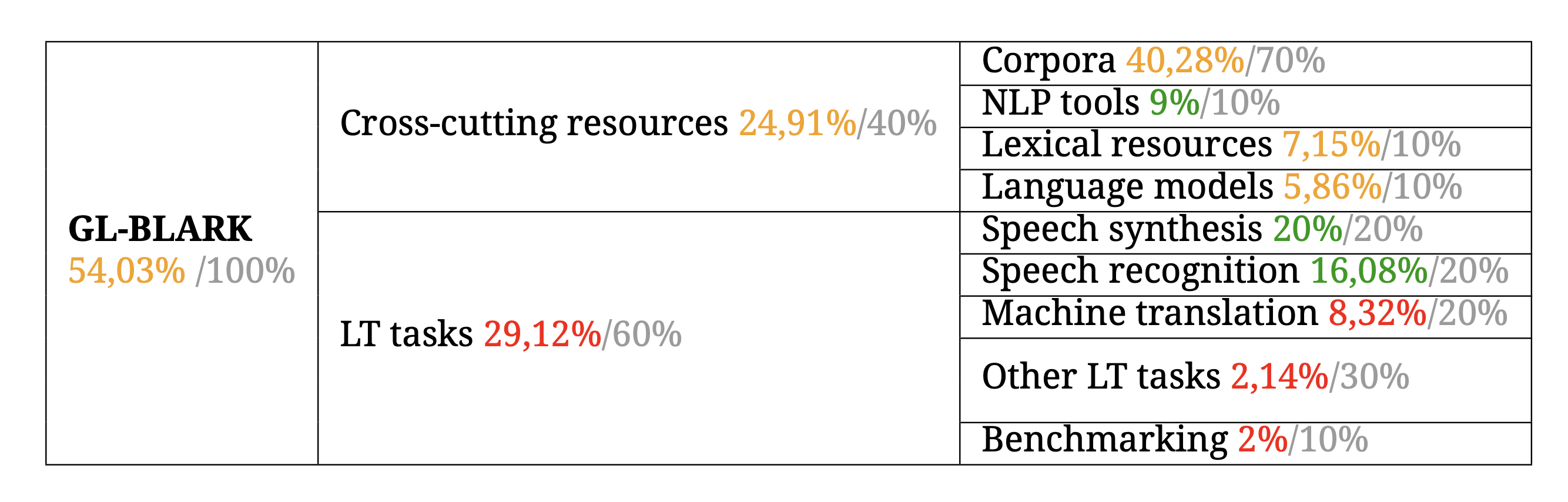
Finally, we present the complete BLARK for Galician. As can be observed, the final result places Galician in an intermediate state in a BLARK designed to assess the situation of minority languages and the minimum requirements to be met in LT. The situation in both transversal resources and specific tasks shows that there is a great deal of work to be done in creating corpora for Galician, both spoken and written, in order to improve the situation in the various tasks.
More information
If you would like to know more about the GL-BLARK project, visit the following link:
https://european-language-equality.eu/wp-content/uploads/2023/04/ELE2_Project_Report_BLARK.pdf

