
What is Lynx?
Lynx is a legal consultation system based on Retrieval-Augmented Generation (RAG), a technology that combines information retrieval from official sources with the generation of contextualized responses, ensuring rigor, traceability, and reliability. It is a RAG designed specifically for the Official Gazette of Galicia (DOG) and other official bulletins, aimed at meeting the need to access public information in natural language. Its goal is for anyone to be able to ask questions in everyday language and obtain responses based exclusively on official documents, always displaying the sources used to ensure their verification.
What problem does it solve?
Access to legal and administrative information remains, to this day, a complex process for many people. The documentation published in the DOG is extensive, technical, and requires knowing precisely where to search and how to interpret the content. In practice, this translates into several recurring problems:
Searches are performed in a manual and inefficient manner.
- It is necessary to have prior knowledge of the structure of the bulletins and legal language.
- The process can generate errors, delays, and frustration, both for citizens and for professionals who consult this information daily.
Lynx was created to address this situation, transforming the consultation of legal documentation into a simple, fast, and accessible process, regardless of the user's level of experience. The tool allows:
- Asking questions in natural language, without needing to know exact legal terms.
- Obtaining precise, well-founded, and transparent responses in a matter of seconds.
- Significantly reducing the time and effort needed to consult official documents.
In this way, Lynx facilitates interaction with DOG information for citizens, public sector staff, media professionals, and anyone who needs access to reliable legal information.
Practical cases
What sets it apart from other technologies?
- Reliability. Unlike other generic systems such as ChatGPT, Lynx does not invent responses: all information comes from official DOG documents.
- Verifiability. Each response includes complete traceability, allowing access to the original document from which the relevant excerpt was extracted.
- Natural language interaction. Lynx enables interaction in natural language and understands queries expressed in colloquial or technical terms, overcoming the limitations of traditional search engines.
- Specialization in the legal domain. The system is designed specifically for official bulletins and legal documentation, which allows better adaptation of retrieval and generation models to the legal-administrative domain.
Main features
- Specialization and local adaptability. Designed for the DOG, with an architecture that facilitates its adaptation to other official bulletins, administrative contexts, or domains where reliable information consultation is needed.
- Rigor and transparency. Each response is traceable in the DOG, which reduces the possibility of errors and increases confidence in the system.
- Time savings and operational efficiency. Lynx helps reduce the time spent on documentary searches, allowing efforts to be focused on higher-value tasks.
- Simple user experience. The user simply asks the question; the system handles searching, filtering, understanding, and responding, always displaying the sources used.
- Modular and scalable architecture. Its architecture allows integrating new sources, models, languages, or functionalities without modifying its basic structure.
- Cutting-edge technology. It combines hybrid retrieval (semantic and keyword-based), reranking, and domain-adjusted generation models.
- Social impact. It promotes the democratization of access to public information, improves transparency, and contributes to reducing the digital divide.
Architecture and design
Lynx's architecture goes beyond a traditional RAG, as it must respond to a series of specific requirements of the legal domain and the Galician linguistic context, which are not present in other fields of application. The following outlines the key points that Lynx must resolve and how it manages them with its architecture:
- Multilingual context. The system supports queries in Galician, Spanish, English, and other national languages, such as Catalan or Basque, always responding in Galician to ensure linguistic consistency.
- Privacy and data protection in the legal domain. Information published in official bulletins may contain sensitive personal data such as names or ID numbers. For this reason, Lynx incorporates mechanisms to detect and block queries that could enable the tracing of personal data, protecting individual privacy.
- Prevention of malicious behavior. As a publicly accessible tool, Lynx is protected against malicious practices such as prompt injection, i.e., the possibility of a user modifying the behavior of the original model. Lynx ensures that the generated responses always comply with the requirements defined in the original prompt.
- Conversational functionality. Unlike other RAG systems, Lynx allows maintaining a brief conversation around the same query, facilitating follow-up questions within the same session, depending on the language model used and its context window.
- Collection of feedback and continuous improvement. The interface offers users the possibility of evaluating the responses obtained, allowing the imaxin team to incorporate this feedback as part of a continuous improvement process for the tool.
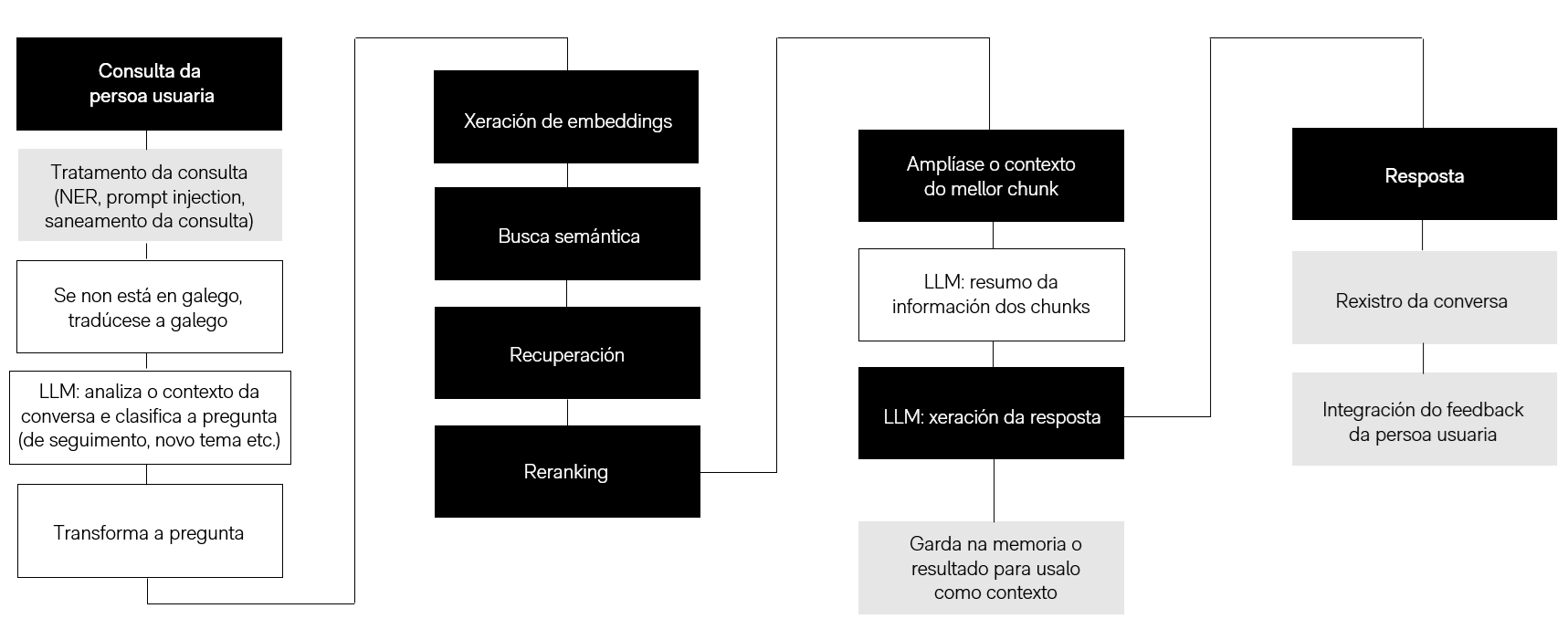
To address all these requirements, Lynx's architecture is structured into four main blocks: database creation, query processing, information retrieval, and response generation.
System Pipeline
1. Database creation
A very important part of a RAG architecture is the text data from which information is extracted, the chunks. For this, the following process was followed:
- Daily scraping of the DOG, from which documents published each day are extracted.
- Document chunking into blocks of approximately 1,200 characters, respecting as much as possible the logical units of the text (paragraphs, sentences, etc.).
- Indexing in the databases: the chunks are indexed in Qdrant for the creation of the embeddings database (dense vectors) [1], while the complete documents and their metadata are stored in Elasticsearch, enabling keyword-based retrieval.
2. Query processing and preparation
Before initiating information retrieval, the user's query goes through a processing and preprocessing step with the goal of improving search quality:
- Cleaning and normalization: strange or irrelevant characters are removed, formatting errors are corrected, and the text is prepared for system interpretation.
- Automatic translation to Galician: using an LLM, the original query is translated into Galician.
- Sensitive data detection: using NER techniques and regular expressions, personal data (such as names or ID numbers) are identified and the query is blocked if necessary.
- Query classification: to maintain conversational functionality, the system determines whether the query is new or a follow-up. In the case of a follow-up, retrieval focuses on the same document as the initial response; if it is new, the search starts from scratch.
- Query reformulation: the LLM adapts the translated query, expanding information, choosing more precise terms, and optimizing retrieval to obtain more relevant and reliable chunks.
3. Information retrieval
In Lynx we use a hybrid retrieval strategy that combines semantic search using dense vectors with lexical keyword-based retrieval, leveraging the best of both approaches to obtain relevant and verifiable chunks. Dense vector retrieval Each chunk of the corpus is indexed as a dense vector in the Qdrant database. Queries are converted into embeddings using the bge-m3 model and semantic retrieval is performed by cosine similarity. This method captures conceptual similarities even when there is no exact word match, improving coverage for complex queries. Keyword retrieval In parallel, we apply lexical retrieval using BM25 in Elasticsearch, capturing matches by exact terms or phrases. This strategy is especially useful for legal queries that include numbers, names, or precise textual expressions. Fusion and reranking The result lists from both strategies are combined using Reciprocal Rank Fusion (RRF), normalizing and integrating the scores. From the fused chunks, we select a candidate set that goes through a finer reranking [2], evaluating relevance, factual fidelity, and contextual relevance. Finally, the 10 most relevant chunks are selected for response generation. Context augmentation To avoid erroneous interpretations or mixing of different laws, the response is generated primarily from the highest-scoring chunk. In addition, context is expanded by adding the immediately preceding and following chunks, thus maintaining the coherence and completeness of the information.
4. Response generation
In responses generated by the LLM, the original document from which the chunk used to generate the response was extracted is always included. Additionally, the user can:
- Review the other retrieved chunks and the annexes to the corresponding documents, in case the selected chunk did not match their query [3].
- Rate the response and leave comments about its accuracy and usefulness, thus contributing to the continuous improvement of the platform.

Monitoring and continuous evaluation
To easily identify areas for improvement or phases of the architecture requiring adjustments, we use a monitoring platform that allows tracking the entire RAG pipeline: query transformation, chunk retrieval, reranking, and response generation. Not only queries and final responses are recorded, but also intermediate attributes, such as scores, extracted documents, source database, and metadata. This allows visualizing the complete flow of each query and quickly detecting where the system can be optimized. Evaluation is one of the key components for any production system, especially in a non-deterministic system like Lynx, where no quality public datasets exist to validate responses. Starting from this premise, we collaborated with researchers from CiTIUS to:
- Create a validation procedure adapted to the system.
- Generate a validation dataset specific to Lynx.
This dataset is integrated into the continuous evaluation system, allowing the quality of responses to be measured and this information to be used to progressively fine-tune and improve the system. Thanks to this approach, we were able to detect deficiencies in the early stages and implement improvements that enriched the architecture and reinforced the system's reliability.
Future of the Lynx project
Even as the official project comes to an end, Lynx will continue to evolve throughout 2026 with new improvements:
- Optimization of retrieval models, to increase the precision and relevance of responses.
- Responses in clear and accessible language, adapted to different audiences and query formats.
- Integration of complex queries using graphs, enabling answers to questions that require navigating relationships between documents and data.
- Renewal of the user interface, facilitating consultation, navigation, and source verification.
- Expansion of continuous evaluation, incorporating validation datasets and using LLM models as automated judges to improve response quality.
These actions will allow Lynx to continue growing as a reliable, transparent, and useful tool for accessing public information quickly and in context.
Conclusion
Lynx represents a step forward in the application of artificial intelligence to the field of public information, combining technical rigor, legal reliability, and usability. This project demonstrates that it is possible to build useful, transparent AI systems aligned with the linguistic and institutional context, bringing real value to society and laying the groundwork for future applications in the field of e-government and legal information. Try Lynx with no commitment.
Contact us for a free trial or to request a quote to implement the system in your official bulletin.
Lynx is a project developed by imaxin within the framework of the IA360 call by the Galician Institute for Economic Promotion (Igape), within the Recovery, Transformation, and Resilience Plan, and funded by the European Union – NextGenerationEU.

[1] Qdrant embeddings are generated with the bge-m3 model, a multilingual model that includes Galician and was specifically designed for retrieval tasks in RAG.
[2] This step was carried out with the bge-reranker-v2-m3 model, a multilingual model specifically trained to perform this task efficiently.
[3] Currently, the model used for query translation and preprocessing, as well as for response generation, is the deepseek.v3-v1 model. This model ensures a context window large enough to allow the user to maintain a conversation. Nevertheless, Lynx's architecture would allow using small LLM models for each phase and switching to the most suitable model for each case.

